Jak pracovat s modulem události & alerting
Pokud je v textu chyba či schází nějaká informace, informujte
support@cibs.cz, jako předmět uveďte název článku.
Seznam níže uvedených akcí lze nalézt v modulu
.
Pojmy
| Název |
Definice |
| Událost |
informace ze zdroje o změně stavu objektu (zařízení) nebo změně nějakého parametru objektu |
| Rozpoznaná událost |
událost, která je na základě filtrů a triggerů identifikovaná z množiny surových událostí |
| Zdroj události |
zdroj, pomocí kterého byla událost mezi surové události vložena |
| Surové události |
halda, do které jsou zachytávány události ze zdrojů |
| Filtr |
množina kritérií, pomocí kterých vznikají ze surových událostí identifikované události |
| Kritérium |
definice testu, který je aplikován na surovou událost |
| Trigger |
nastavení, na základě kterého vznikne na základě identifikované události alert |
| Alert |
zpráva nebo upozornění, které je vygenerované na základě předem definovaných filtrů a triggerů z množiny surových událostí |
Jaké máme zdroje událostí?
Zdrojem události může být:
- SNMP TRAP - Události z tohoto zdroje jsou mezi "Surové události" vkládány na základě SNMP trapů ze zařízení, přijatých DX serverem.
- SYSLOG - Události z tohoto zdroje jsou mezi "Surové události" vkládány na základě hlášení, zaslaných zařízeními na syslog server běžící na DX serveru.
- Monitoring - dostupnost zařízení - Události s tímto zdrojem jsou v záložce "Surové události" uvedeny v případě, že u zařízení došlo k výpadku nebo obnově činnosti.
- Definováno uživatelem - Události z tohoto zdroje mohou být vkládány vlastním monitorovacím nástrojem CP přes dohodnuté rozhraní (například WebServices). Dále jsou jako události z tohoto zdroje evidovány informace o aktualizaci parametrů zařízení, např. aktualizace IPTV STB připojené pod Nangu.
- Monitoring - hodnoty - Události s tímto zdrojem jsou uvedeny v záložce "Surové události" pouze v případě, že je nadefinován nějaký filtr s tímto zdrojem a na některém zařízení, na něž je aplikovatelný, dojde ke změně odpovídající hodnoty.
Stručný popis funkcionality
1. Všechny události jenž vygenerují
zdroje události jsou zachytávané do záložky
Surové události.
2. Pomocí filtrů definovaných v záložce
Filtry se z množiny
surových událostí vyberou jen ty, které nás zajímají a tím se z nich stanou
rozpoznané události.
3. Množinu rozpoznaných událostí lze spatřit v záložce
Rozpoznané události – vyfiltrované události ze záložky
Surové události.
4. Na tuto vyfiltrovanou množinu lze v záložce
Triggery alertů nadefinovat trigger.
5. Pokud identifikovaná událost splňuje podmínky
nadefinovaného triggeru, vzniká alert. O historii těchto vygenerovaných a vyexpedovaných alertů nás informuje záložka
Historie alertů.
6. Vedle alertů expedovaných pomocí SMS nebo e-mailu je hlavním výstupem tohoto modulu záložka
Wallboard, kde operátor zjistí všechna zařízení s aktuálně notifikovaným problémem. Pokud zde není žádné zařízení, je vše v pořádku.

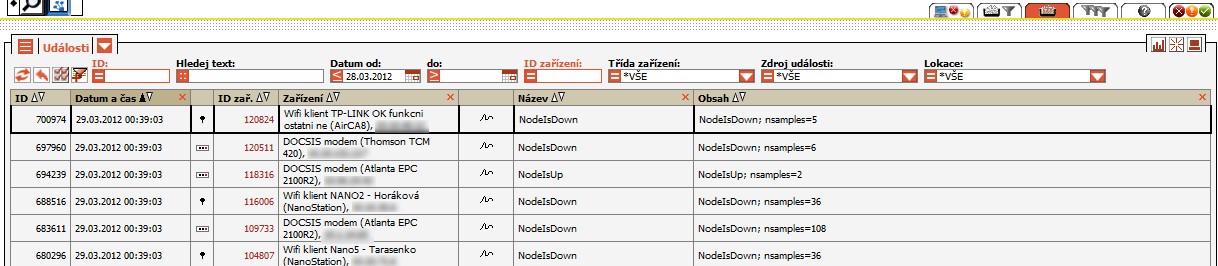
Záložka "Surové události"

Každá událost se váže ke konkrétnímu zařízení, na němž je možné přímo v modulu provést následující operace:
 "Online měření zařízení, na kterém byla identifikována vybraná událost"
"Online měření zařízení, na kterém byla identifikována vybraná událost"
 "Restart zařízení, na kterém byla identifikována vybraná událost"
"Restart zařízení, na kterém byla identifikována vybraná událost"
 "Ping na IP adresu zařízení na kterém byla identifikována vybraná událost"
"Ping na IP adresu zařízení na kterém byla identifikována vybraná událost"
Surové události třídy SIM a GSM Proxy
Pro zařízení třídy SIM a GSM Proxy je možné si v záložce
Surové události zobrazit události těchto zařízení, které se využívají pro služby třídy "Hlasová služba GSM" nebo "Balíček GSM".

Seznam surových událostí třídy GSM Proxy
- Quadruple.ImportCdr.FileDownload
- Quadruple.ImportCdr.UnknownGid (ID služby z CRM Materny)
- Quadruple.ImportCdr.SqlError
- Quadruple.ImportCdr.FileDelete
- Quadruple.ImportEdr.FileDownload
- Quadruple.ImportEdr.UnknownGid (ID služby z CRM Materny)
- Quadruple.ImportEdr.SqlError
- Quadruple.ImportEdr.FileDelete
- Quadruple.ImportCdrEdr.DirList
- Quadruple.ImportCdrEdr.Login
- Quadruple.ImportCdrEdr.Failed
Pro zmíněné události si lze nastavit trigger alertů se šablonou "GSM_IMPORT_NOTIFY".
Seznam surových událostí třídy SIM
- Quadruple.SimUpdate.SOAPError
- Quadruple.SimUpdate.AppBusError (logování SQL chyb)
Pro zmíněné události si lze nastavit trigger alertů se šablonami "GSM_SOAP_NOTIFY" a "GSM_APPBUS_NOTIFY".
Seznam surových událostí třídy SIM pro EDR notifikace
Příklad použití: nastavení odesílání mailu na konkrétní EDR operaci (třeba při portaci čísel).
Události lze filtrovat na záložce Surové události, dle sloupce Název (úroveň category.operation) a Obsah (úroveň service).
Nastavení pro notifikaci lze provést na záložce
Filtr s těmito parametry:
- Zdroj události: Zpráva od zařízení
- Událost: Udává se výraz ve spojení názvu až do úrovně category.operation, příklad: SRV.ACT-DONE. Pro všechny události SRV lze zapsat znakem % jako SRV.%
- Regulérní výraz: v případě, že chcete notifikovat i úroveň service, lze do regulérního výrazu zapsat jako #service=hodnota#, příklad: #service=m_barringByCustomer/outgoingSms#
- ostatní parametry dle vzorového snímku
Úroveň category může obsahovat (zdroj MVNE_CDR_format_and_fields):
- SUB - Subscription
- SRV - Supplemental & VAS Services
- ACC - Account Balance & Cost Control
- CHG - Charging
Úroveň operation může obsahovat (zdroj MVNE_CDR_format_and_fields):
- NEW - new entity is created
- ACT-REQ - activation of simProfile service is requested
- ACT-DONE - activation of simProfile service is finished by HMNO
- DEACT-REQ - deactivation of simProfile service is requested
- DEACT-DONE - deactivation of simProfile service is finished by HMNO
- SET-REQ - new value of simProfile service is requested
- SET-DONE - new valie of simProfile service is set by HMNO"
Seznam úrovní service je k dispozici v akutálním PMW service catalogue.
Příklad nastavení filtru:

Šablonu pro trigger si CIBS partner nastavuje sám (
modul Šablony ), kdy si tuto šablonu použije v nastavení
triggeru .
K těmto zařízením navazují následující funkcionality:
Záložka "Filtry"
Jak vložit skupiny filtrů?
V záložce
Filtry, tabulka "Skupiny filtrů" zvolíme akci

"Vložení nové skupiny filtrů".
Při zakládání nového filtru bez ohledu pro jaký zdroj události bude aplikován je nejdříve nutné vybrat následující atributy

| Atribut |
Popis |
| CIBS partner |
Výběrem konkrétního CIBS partnera výrazně zužíte a zrychlíte vyhledávání zařízení. V položce Zařízení pak budou nabízena i koncová zařízení zákazníků. |
| Lokace |
Výběrem konkrétní lokace výrazně zužíte a zrychlíte vyhledávání zařízení. V položce Zařízení pak budou nabízena i koncová zařízení zákazníků. |
| Typ zařízení |
Typ zařízení pro který bude tato skupina filtrů platná - je třeba nejpre vybrat položku Třída zařízení. |
| Třída zařízení |
Třída zařízení, pro kterou bude tato skupina filtrů platná - tento atribut je povinný poněvadž na základě jeho vybrání jsou vypsány parametry této třídy při použití zdroje události "Monitoring - hodnoty" |
| Popis skupiny |
Podrobný popis filtru |
| Název skupiny |
Název filtru, tento název je důležitý při vytváření triggeru. |
| Zařízení |
Konkrétní zařízení, na které se má tato skupina filtrů aplikovat. Nejprve je třeba vybrat položku Třída zařízení. |

Jednotlivé filtry lze dle názvosloví řadit do skupin a s těmito skupinami následně operovat. Jednotlivé skupiny je možné třídit dle zdroje události či stavu filtrů. Filtry nejsou jen pro evidenční účely. Je potřeba, si uvědomit, že tím, co nabývá nějakého stavu, je dvojice "Zařízení - Skupina filtrů".
Na zařízení mohu mít více skupin filtrů, které indikují stav zařízení v různých ohledech. Například na DOCSIS modemu mohu mít "Výpadky" (ze zdroje událostí "Monitoring - dostupnost zařízení") a bude "OK", protože modem je dopingatelný a "CNR" (ze zdroje "Monitoring - hodnoty") a ta může být na stejném zařízení "CRITICAL", protože poměr signál/šum je hodně špatný, a díky tomu to v reálném provozu nemusí moc fungovat, i když zařízení není "mrtvé".
Pokud má alertování fungovat správně, je pro většinu smysluplných způsobů použití nezbytné pro každý filtr, který detekuje stav "CRITICAL" nebo "WARNING" mít nadefinován i komplementární filtr, který vygeneruje událost se stavem "OK". Z tohoto důvodu při pokusu o vytvoření skupiny filtrů
pouze pro stav "CRITICAL" nebo "WARNING" nám uložení neprojde, dialog zahlásí, že musí být vytvořen i odpovídající filtr pro stav "OK". Když by se to nenakonfigurovalo tímto způsobem tak zařízení, na nichž jednou nastala chyba, by navždy svítita na wallboardu a při dalším výskytu chyby by se nevygeneroval žádný alert (pokud by trigger alertu nebyl nadefinován se zatržítkem
"I nezměněný stav").

Nyní se již nastavení jednotlivých filtrů liší v závislosti na vybraném
Zdroji události
1) Ukázka vložení filtru pro zdroj události Monitoring - dostupnost zařízení
Na následujícím obrázku lze spatřit vytváření nové skupiny filtrů s použitím zdroje události
Monitoring - dostupnost zařízení.
| Atribut |
Popis |
| Zdroj události |
Vybraná hodnota Monitoring - dostupnost zařízení |
| Událost |
Na výběr máme k dispozici událost pro výpadek zařízení, obnovu zařízení nebo nově monitorované zařízení. Poslední zmiňované využijeme v případě, že zařízení nebylo dosud nikdy omonitorováno a my chceme být o jeho prvním monitorování informování. Např. první zapojení modemu zákazníka. |
| Stav |
Tento atribut pomáhá popsat stav zařízení, k dispozici jsou nadefinované stavy: / kritický / varování / OK / nemění se. Například když zařízení neodpoví na monitoring v 10 minutovém intervalu chceme být pouze varování, když ovšem neodpoví v 60 minutovém intervalu, pak je již závažnost kritická. Naopak když je vypadlé zařízení obnoveno, pak použijeme stav OK. Poslední stav "Nemění se" lze použít v případě, kdy chceme na daném zařízení filtrovat události, které nutně neznamenají výpadek ani obnovu zařízení, např. na apachi chceme sledovat určité veličiny. |
| Pojmenování |
Pojmenování filtru - tento název je zároveň názvem události, identifikované tímto filtrem |
| Poznámka |
Nepovinný atribut sloužící pro lidský popis toho co má filtr dělat |
| Délka výpadku |
Zde se hodnota vyplňuje pouze v případě, že zvolíme událost "Výpadek zařízení". Kritérium je splněno jestliže zařízení neodpovídá na požadavky monitoringu po tuto dobu. |
| Sruzumitelný název |
Atribut určený pro komentář |

2) Ukázka vložení filtru pro zdroj události SNMP trap
Na následujícím obrázku lze spatřit vytváření nové skupiny filtrů s použitím zdroje události
SNMP trap.
| Atribut |
Popis |
| Zdroj události |
Vybraná hodnota SNMP trap |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj (například OID identifikující typ trapu pro SNMP trap) |
| Stav |
Tento atribut pomáhá popsat stav zařízení, k dispozici jsou nadefinované stavy: / kritický / varování / OK / nemění se. Například když hodnota OID (např. iso.3.6.1.4.1.2021.8.1.100.1) je rovna 0 pak je zařízení v pořádku. Když je ovšem hodnota OID větší než 0 pak je na zařízení problém. Poslední stav "Nemění se" lze použít v případě, kdy chceme na daném zařízení filtrovat události, které nutně neznamenají změnu stavu zařízení). |
| Pojmenování |
Pojmenování filtru - tento název je zároveň názvem události, identifikované tímto filtrem |
| Poznámka |
Nepovinný atribut sloužící pro lidský popis toho, co má filtr dělat |
| OID |
OID z obsahu SNMP trapu, jehož hodnota je porovnávána |
| Operátor |
Operátor pro porovnání hodnoty: >, <, >=, <=, =, LIKE |
| Hodnota |
Zde se určí číselná hodnota, jež je pomocí zvoleného operátoru porovnána s hodnotou OID |
| Sruzumitelný název |
Atribut určený pro komentář |

3) Ukázka vložení filtru pro zdroj události Syslog
Na následujícím obrázku lze spatřit vytváření nové skupiny filtrů s použitím zdroje události
Syslog.
| Atribut |
Popis |
| Zdroj události |
Vybraná hodnota Syslog |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj (například OID identifikující typ trapu pro SNMP trap) |
| Stav |
Tento atribut pomáhá popsat stav zařízení, k dispozici jsou nadefinované stavy: / kritický / varování / OK / nemění se. Poslední stav "Nemění se" lze použít v případě, kdy chceme na daném zařízení filtrovat události, které nutně neznamenají změnu stavu zařízení). |
| Pojmenování |
Pojmenování filtru - tento název je zároveň názvem události, identifikované tímto filtrem |
| Poznámka |
Nepovinný atribut sloužící pro lidsky srozumitelný popis toho, co má filtr dělat |
| OID |
OID použité pro filtrování |
| Operátor |
Nepovinný operátor pro porovnání nalezené match-group se zadanou hodnotou: >, <, >=, <=, =, LIKE |
| Hodnota |
Nepovinná hodnota, s níž, jestliže je zadána, bude porovnána nalezená match-group pomocí zvolenáho operátoru |
| Sruzumitelný název |
Atribut určený pro komentář |
4) Ukázka vložení filtru pro zdroj události Monitoring - hodnoty
Na následujícím obrázku lze spatřit vytváření nové skupiny filtrů s použitím zdroje události
Monitoring - hodnoty.
Přes SNMP nyní monitorujeme na zařízení různé hodnoty a ukládáme je do databázových tabulek z nichž pak kreslíme grafy. Díky tomuto zdroji událostí můžeme v okamžiku uložení dat do tabulek zároveň vybrané (operátorem nastavené) hodnoty zkontrolovat a když vybočí z určitého rozsahu, vygenerovat z nich událost, která následně může vyvolat alert (a tedy vést k poslání mailu nebo SMS, případně spuštění workflow). Mail je tak možné poslat například pokud nějaké zařízení začne mít příliš slabý signál. Na níže uvedeném obrázku je nastaven filtr, který hlídá využití CPU na zařízení, k tomuto účelu porovnává OID hodnotu pomocí operátoru s uživatelsky zvolenou konstantou. V případě, že vzroste load CPU nad 50% je vygenerována surová událost na níž tento filtr zareaguje. Dalším postupem může být pro tento filtr nadefinování triggeru, který následně odešle na operátora či servisni skupinu sms, email, případně bude spuštěna automatizace (workflow).
| Atribut |
Popis |
| Zdroj události |
Vybraná hodnota Monitoring - hodnoty |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj |
| Stav |
Tento atribut pomáhá popsat stav zařízení, k dispozici jsou nadefinované stavy: / kritický / varování / OK / nemění se. Například když hodnota OID (HOST-RESOURCES-MIB::hrProcessorLoad.1) je větší než 50 pak se začíná zvyšovat load procesoru, ohodnotíme to stavem varování a chceme, aby na tento stav reagoval trigger. Když ovšem hodnota OID je menší nebo rovna 50 pak je již load procesoru v pořádku. Poslední stav "Nemění se" lze použít v případě, kdy chceme na daném zařízení filtrovat události, které nutně neznamenají změnu stavu zařízení. |
| Pojmenování |
Pojmenování filtru - tento název je zároveň názvem události, identifikované tímto filtrem |
| Poznámka |
Nepovinný atribut sloužící pro lidský popis toho co má filtr dělat |
| Naměřená hodnota |
OID monitorované na zařízení, jehož hodnotu toto kritérium pomocí zvoleného operátoru porovnává s hodnotou zadanou v kritériu |
| Operátor |
Operátor pro porovnání hodnoty: >, <, >=, <=, =, LIKE |
| Konstanta / parametr |
Zde máme na výběr dvě možnosti, v případě, že vybereme "Konstanta" bude hodnota zadaná ve formuláři "Hodnota" porovnávána s operátorem. Pokud zvolíme "Parametr", ve formuláři "Hodnota" se zobrazí všechny v databázi nadefinované parametry pro vybranou třídu zařízení. Z tohoto důvodu je atribut "Třída zařízení" povinný a opět dojde k porovnání s operátorem. |
| Hodnota |
Číselná hodnota, s níž je pomocí zvoleného operátoru porovnávána konstanta nebo parametr zařízení |
| Srozumitelný název |
Atribut určený pro komentář |

Ukázka vložení filtru pro zdroj události TX levelu a CNR modemu
| Atribut |
Popis |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj (například OID identifikující TX level: DOCS-IF-MIB::docslfCmStatusTxPower.2 |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj (například OID identifikující CNR modemu: DOCS-IF-MIB::docslfSiqQSignalNoise.3 |


5) Ukázka vložení filtru pro zdroj události Definovaný uživatelem
Na následujícím obrázku lze spatřit vytváření nové skupiny filtrů s použitím zdroje události
Definovaný uživatelem.
Např. je možné sledovat úspěšnost provedení aktualizace pro zařízení
IPTV SetTopBox nebo
OTT identita z NANGu. Jsou k dispozici 2 události:
DeviceUpdateError (chyba při konfiguraci zařízení) a
DeviceUpdate (úspěšná konfigurace zařízení).
| Atribut |
Popis |
| Zdroj události |
Vybraná hodnota Definovaný uživatelem |
| Událost |
Filtr na druh události, specifický pro zvolený zdroj |
| Stav |
Tento atribut pomáhá popsat stav zařízení, k dispozici jsou nadefinované stavy: / kritický / varování / OK / nemění se. Poslední stav "Nemění se" lze použít v případě, kdy chceme na daném zařízení filtrovat události, které nutně neznamenají změnu stavu zařízení. |
| Pojmenování |
Pojmenování filtru - tento název je zároveň názvem události, identifikované tímto filtrem |
| Poznámka |
Nepovinný atribut sloužící pro lidský popis toho co má filtr dělat |
| Regulerní výraz |
Zde je možné si sestavit regulerní výraz s požadovanou akcí. Popis výrazu jenž je uveden na obrázku najdete níže. |
| Operátor |
Operátor pro porovnání hodnoty: >, <, >=, <=, =, LIKE |
| Srozumitelný název |
Atribut určený pro komentář |
Příklad pro třídu zařízení IPTV SetTopBox (analogicky lze použít u OTT identity):

Popis regulerního výrazu
| Znak |
Popis |
| / |
ohraničení |
| ^ |
začátek textu / řádku |
| $ |
konec konec textu |
| () |
kulaté závorky ohraničují skupinu |
| ? |
žádné nebo jedno opakování předchozího |
| ? |
pojmenování skupiny (musí být hned za úvodní závorkou). Objecně se pak jde odkázat na skupinu tímto názvem |
| .(tečka) |
jakýkoli znak |
| * |
libovolný počet opakování přechozího znaku skupiny nebo třídy znaků |
| S |
flag, který říká, že jde o víceřádkový regulerní výraz |
Toto je samozřejmě pouze stručný komentář regulerních výrazů uvedených na obrázku. Pro bližší pochopení je vhodné si stáhnout dokumentaci k regulerním výrazům.
Při nastavení tohoto filtru se rozpoznané události kromě modulu Události & Alertingu zobrazují také v modulu "Koncová zařízení" nebo "Cesta sítí", tabulka "Události zařízení".

Záložka Rozpoznané události

Každá událost se váže ke konkrétnímu zařízení, na němž je možné přímo v modulu provést následující operace:
"Online měření zařízení, na kterém byla identifikována vybraná událost"
"Restart zařízení, na kterém byla identifikována vybraná událost"
"Ping na IP adresu zařízení na kterém byla identifikována vybraná událost"
Záložka Triggery alertů

Jak vytvořit nový trigger?
V záložce
Triggery alertů, tabulka "Skupiny filtrů" zvolíme akci
"Vložení nového triggeru".

| Atribut |
Popis |
| Skupina filtrů |
Skupina filtrů která aktivuje tento trigger. |
| Zařízení |
ID zařízení |
| Stav sk. filtrů |
Udává stav skupiny filtrů, na výběr jsou hodnoty kritický / varování / OK / nemění se Tyto stavy jsou shodné se stavy když vytváříme nový filtr v záložce "Filtry". |
| I nezměný stav |
Triggeruje i události, které nemění stav skupiny filtrů. To, co alertujeme bez tohoto zatržítka, je "ZMĚNA STAVU ZAŘÍZENÍ". |
| Typ |
Udává typ upozornění na daný trigger, na výběr jsou hodnoty sms, email, CIBS workflow. Pomocí CIBS workflow lze nastavit jakoukoli akci ze seznamu spustitelných akcí, viz dokumentace workflow (automatizace). Např. aby při výpadku nebo obnově zařízení došlo k vytvoření servisního procesu. Operátor si pouze nadefinuje filtr, který zvolí při vytváření triggeru a jako typ upozornění zvolí CIBS workflow, následně je nutné kontaktovat support, aby toto workflow přidal do databáze. |
| Cíl |
Udává cílovou skupinu na kterou bude aplikován trigger, na výběr jsou hodnoty operátor, servisní skupina, členové skupiny |
| Šablona |
Udává typ použité šablony ze seznamu nadefinovaných šablon pro příslušný trigger. |
| Operátor/Skupina |
Udává jméno konkrétního operátora, případně název skupiny na které bude zasíláno upozornění triggeru. Vzhledem k tomu, že je modul nadlokační jsou zde zobrazeny jména operátorů, kteří mají právo CT na danou lokaci. Pokud mají operátoři LEVEL 255, tak je vidí jen operátoři s LEVEL 255. Ostatní vidí vše co má level menší než 255 nezávisle na tom, zda sami mají větší nebo menší level (operátor s level 50 tedy vidí i operátora s 254, nevidí ale 255). |
Ikona obálky ve druhém sloupci charakterizuje způsob zasílání alertu, v tomto konkrétním případě se jedná o upozornění formou emailu.
V případě, že dáme trigger editovat a uložíme, dojde automaticky k vytvoření nového triggeru s nastavením původně editovaného. Původně editovaný trigger se zneaktivní. Důvodem tohoto chování je možnost náhledu na historicky vygenerované události, kde potřebujeme vidět, nastavení triggeru, který byl použit u události v době jejího vytvoření. Pokud bychom při editaci triggeru nevytvářeli nový, ale pouze prováděli přepisování, pak by při zpětném náhledu nebylo možné zjistit původní nastavení triggeru.
Šablony pro trigger alertu se zobrazují následovně:
- existuje pouze definice globální šablony = zobrazí se
- neexistuje žádná definice globální šablony ani lokační šablony = nevalidní stav, nezobrazí se, není co
- existuje pouze definice lokační šablony = zobrazí se
- existuje definice globální šablony a i definice lokační šablony a šablony mají shodný název = zobrazí se pouze šablona lokační
Ukázka nastavení triggeru pro TX level a CNR modemu


Definice nastavení monitoringu pro zařízení Mikrotik router
Pro monitoring Mikrotik router je potřeba:
- v záložce Triggery alertů vytvořit triggery pro skupinu filtrů "monitoring Mikrotik". Jeden filtr se šablonou MONITORING_NODE_DOWN a druhý filtr MONITORING_NODE_UP, které se liší stavem skupiny filtrů. U filtrů můžete definovat určení cíle triggeru dle potřeby (email, sms), cíle (operátor, servisní skupina, členové skupiny) a operátora/Skupiny. Detailní popis polí v části Jak vytvořit nový trigger? .


Záložka Historie alertů

Záložka Wallboard

Na tomto screenu lze vidět, že v současné situaci existují 2 zařízení u nichž dochází k určité nekonzistenci.
Záznam o provedeném manuálním vložení události se stavem "OK" lze spatřit v modulu
Rozpoznané události. Takovouto událost poznáme na první pohled dle popisu ve sloupci "Událost", kde je uvedeno Manual acknowledge. Např. následující screen.

Při prokliku na název zařízení se dostaneme do modulu "Cesta sítí", kde v tabulce "Události zařízení" lze spatřit opět záznam o manuálním vložení události se stavem "OK".

Stromová kontrola alertů
Systém událostí a alertů v CIBSu je propojen s CIBSovým monitoringem
tak, že využívá jeho data, není ale přímo jeho součástí. Oba subsystémy
jsou na sobě relativně nezávislé a v čase asynchronní.
CIBSový monitoring funguje plošně - periodicky se monitorují zařízení
jednotlivých typů. Okamžik, kdy bude zařízení monitorováno, tedy nezávisí
na jeho zapojení v topologii sítě.
Alerty událostí, týkajících se výpadků a obnovení činnosti zařízení,
které jsou generovány monitoringem, je možné nastavit tak, aby alert byl
potlačen při výpadku nadřazeného zařízení, tak, aby například při
výpadku některého ze zařízení páteřní infrastruktury sítě nebyly
zbytečně alertovány výpadky jednotlivých AP a klientských zařízení,
k nimž nutně dojde zároveň, ale jsou v tomto případě pouze symptomem
problému s nadřazeným zařízením. (Stejný mechanismus potlačení alertu
samozřejmě funguje i při výpadku samotného monitoringu.)
Funkcionalita stromová kontrola alertů byla vytvořena za účelem
zamezit zbytečným odesíláním alertů. Uvedu na příkladu. Při výpadku zařízení dojde k odeslání alertů na tomto zařízení a všech podřízených zařízeních (v případě, že není síť ve skutečnosti zokruhovaná). V případě sms je odeslání více takovýchto sms zbytečné a proto přichází na řadu stromová kontrola alertů.
Jak stromová kontrola funguje?
Nejdříve je nutno zmínit několik důležitých pojmů týkajících se monitorování zařízení. Každé zařízení monitorujeme buď přes SNMP nebo PING nebo obojí co 5 minut. Uvedu na příkladu. Máme infrastrukturní zařízení (např. viz následující obrázek Router
RB433AH) na němž je nastaven filtr se zdrojem události
Monitoring - dostupnost zařízení s nastaveným intervalem výpadku 10 minut. Dále máme koncové zařízení (např. viz následující obrázek Wifi klient Nano 5) na němž je nastaven filtr se zdrojem události
Monitoring - dostupnost zařízení s nastaveným intervalem výpadku 15 minut.

Modelový příklad jak se vyhodnocuje výpadek zařízení:
Měřeníme každých 5 minut.
- 1 vzorek měření: Nenaměřili jsme žádné hodnoty pro koncové zařízení.
- 2 vzorek měření: Nenaměřili jsme žádné hodnoty pro infrastrukturní zařízení jenž je ve stromové struktuře nad koncovým zařízením a opět jsme nenaměřili žádné hodnoty pro koncové zařízení.
- 3 vzorek měření: Nenaměřili jsme žádné hodnoty pro koncové ani infrastrukturní zařízení.
Tím pádem splňujeme podmínky 15 minutové nečinnosti koncového zařízení a 10 minutové nečinnosti infr. zařízení.
V tomto případě by bez použití funkcionality stromové kontroly alertů pří výpadku infrastrukturního zařízení (Router
RB433AH) okamžitě došlo k odeslání alertů např. sms nejen tohoto inf. zařízení, ale také všech zařízení nacházející se pod ním (Wifi klient Nano 5). S použitím funkcionality stromové kontroly alertů je však situace jiná. Před odesláním alertu se zkontroluje stav nadřazeného zařízení:
- Pokud je nadřazené zařízení rovněž ve výpadku a má nastavený stejný cíl triggeru, k odeslání alertu nedojde.
- V případě, že nadřazené zařízení je rovněž ve výpadku, ale jeho cíl triggeru je jiný k odeslání alertu dojde.
- V případě, že nadřazené zařízení není vůbec ve výpadku, pak k odeslání alertu samozřejmě dojde.
Důvodem těchto podmínek je, že když máme u každého zařízení nastaven trigger s jiným cílem např. technikem pak je žádoucí, aby se trigger odeslal oboum lidem. Naproti tomu, když je u obou zařízení nastaven trigger na stejného technika, pak není nutné, aby se technikovi odeslaly sms dvě.
Z dříve uvedeného (relativní nezávislost monitoringu a alertingu
a plošná povaha CIBSového monitoringu) však vyplývá, že pokud je hranice
pro detekci výpadku nastavena u všech zařízení stejně, není možné zaručit,
že při výpadku celé větve sítě (případně i celého monitoringu) vznikne
událost o výpadku nadřazeného infrastrukturního zařízení dříve, než události
o výpadku podřízených zařízení. A jestliže je výpadek podřízených zařízení
je detekován dříve, nemůže popsané potlačení "jejich" alertu na základě
kontroly nadřazených zařízení zafungovat.
Z tohoto důvodu velmi doporučujeme v případě, že je požadována funkčnost
potlačení alertů výpadku podřízených zařízení při výpadku nadřazených,
nastavit pro jednotlivé typy zařízení podle jejich místa v topologii
sítě hranice pro detekci výpadku, které nejsou shodné, ale navyšují se
směrem k nižším úrovním.
Lze doporučit například tato nastavení:
- Výpadek RM - 10 minut. Kontrola pak je schopná "odchytit" kromě
situace, kdy fakticky vypadne RM, i potenciální výpadek samotného
monitoringu. Pokud toto není požadováno, lze tuto úroveň vynechat
a hranice na dalších úrovních o 5 minut snížit.
- Výpadek infrastrukturních zařízení - 15 minut.
- Výpadek klientských zařízení - 20 minut.
Systém umožní prostřednictvím práva per operátor zobrazit v nástrojové liště ikonu s notifikovaným problémem na zařízeních např. výpadek zařízení, pokles signálu...V pravé dolní části ikony je v závorce uveden počet těchto zařízení.

Tuto funkcionalitu lze nastavit pomocí práva
GLOBAL_NET_ALERTS.VIEW v modulu administrátoři.
Funkcionalitu je rovněž možno zapnout pro celou lokaci. V takovém případě je nutné kontaktovat support, který vloží do configu záznam s hodnotou
GLOBAL_NET_ALERTS.VIEW

Právo může nabývat následujících hodnot:
- INFRASTRUCTURE - notifikace pouze infrastrukturních zařízení
- ALL - notifikace všech zařízení bez ohledu na to, zda-li jsou infrastrukturní nebo koncová
V závislosti na nastavené hodnotě se následně zobrazuje příslušný počet notifikovaných zařízení v pravé dolní části ikony.
Zapnutí/vypnutí alertingu na zařízení
Proklikem na název zařízení nacházejícího se na wallboardu se dostaneme na detail zařízení v modulu "Cesta sítí". Zde je možné využít akci

"Dočasné potlačení alertů při výpadku zařízení".


Popis atributů dialogu
| Název |
Popis |
| Vypnutí alertu |
Zapnutí nebo vypnutí alertování |
| Datum |
Datum, do kterého bude alerting vypnutý |
| Čas |
Čas, do kterého bude alerting vypnutý |
| I podřízená zařízení |
Včetně všech podřízených zařízení ve stromové struktuře |
| Info |
Podrobný popis akce která nastane |
Odesláním dialogu se provede nastavení/vymazání časového razítka do parametrů zařízení. Parametr je editovatelný včetně smazání.

Při generování alertu pro zařízení se tyto parametry kontrolují. Pokud je nastaven do budoucna, pak se alert nevygeneruje, ale do logu (záložka "Historie alertů") se uvede, že nebyl "expedován". Zobrazení je řešeno textovou poznámkou u záznamu alertu s textem například "Na zařízení nastaven downtime do 2014-04-17 07:44:00", dále jsou alerty, jejichž doručení bylo potlačeno buď downtimem nebo stromovou kontrolou zobrazovány jinou barvou (červené pozadí).


Zpět na obsah:
Jak pracovat s modulem události & alerting
Související odkazy
Grafické uživatelské rozhraní).
Odkazující články
Zpět na obsah:
Jak pracovat s modulem události & alerting


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}